How to Connect Claude Code to Zoom Transcripts | April 2026
Learn how to connect Claude Code to Zoom transcripts using Spinach's MCP server. Give your coding agent meeting context for better development. April 2026
 Maintouch
Maintouch
AI coding agents are now running production systems. Anthropic’s 2026 Agentic Coding Trends Report found that engineering teams across startups and enterprises have moved coding agents from experimental to production, shipping real features to real customers. But there’s a blind spot holding these agents back: the context from your meetings never makes it into the agent’s working memory. Every sprint planning call, every design review, every architecture debate lives in a separate silo. This article walks you through how to close that gap by connecting Claude Code directly to your Zoom transcripts.
TLDR:
- Connect Claude Code to Zoom transcripts so your coding agent understands decisions made in meetings
- Spinach’s MCP server gives Claude Code searchable access to your full meeting history
- Teams cut incident investigation time by 80% when Claude Code references war room transcripts
- Centralized transcript architecture lets Claude Code query across all teams and projects organization-wide
- Spinach captures Zoom meetings org-wide and feeds structured data to Claude Code via MCP, APIs, and webhooks
Why Zoom Transcripts Are a Critical Input for Claude Code
Claude Code is an AI-powered coding assistant built to help you build features, fix bugs, and automate development tasks by understanding your entire codebase. It works across multiple files and tools, and can connect to external data sources through the Model Context Protocol to read design docs, update tickets, or pull relevant data. That’s a powerful setup. But power only goes so far when context is missing.
Here’s the gap: developers sit in meetings, standups, design reviews, and client calls every single day. Those conversations are full of decisions, requirements, and technical context that directly shape how code should be written. What did the product team decide about the new API structure? What edge case did the client flag in last Tuesday’s call? That information usually lives in a separate app or gets buried in someone’s notes.
When Zoom transcripts stay isolated, Claude Code is left guessing. It can read your files, but it can’t read the room. The result is a coding agent working without the full picture, which means more back-and-forth, more misaligned implementations, and more time spent re-explaining decisions that were already made. Connecting your AI meeting notes to Claude Code closes that loop, giving the agent the context it actually needs to do its job well.
What Connecting Claude Code to Zoom Transcripts Unlocks
Feeding Zoom transcript data into Claude Code changes what the agent can actually do. It understands your codebase and why it exists, what it needs to accomplish. Every recorded conversation becomes searchable context, so when you’re building a feature, you can surface exactly what the product manager said about requirements in the last sprint planning call. Advanced AI transcription systems integrate LLMs to go beyond raw transcriptions, delivering meeting summarization, topic modeling, and question answering directly within transcripts.
Development Context That Persists Across Sessions
Without transcript access, Claude Code starts fresh every session. With it, the agent carries forward user stories, acceptance criteria, and edge cases discussed in planning meetings. That means fewer clarifying questions, fewer misaligned implementations, and a tighter feedback loop between what was discussed and what gets built. You can even query across weeks of meeting transcription output to surface architectural decisions made months ago.
Automated Documentation Generation
Transcripts also become raw material for technical documentation. Claude Code can draft PRDs, API specs, and architecture decision records pulled directly from recorded technical discussions. Pair that with Spinach AI tool for automated meeting notes and you’ve got a documentation workflow that practically runs itself, with Claude Code handling the heavy lifting on synthesis.
How Spinach Bridges Zoom and Claude Code
Spinach operates as the conversation data layer sitting between your Zoom meetings and Claude Code. It captures meetings automatically, structures transcripts with speaker attribution and topic segmentation, then exposes that content through integrations Claude Code can actually consume. The MCP server is one primary mechanism here, alongside APIs and webhooks for programmatic access to structured meeting data.
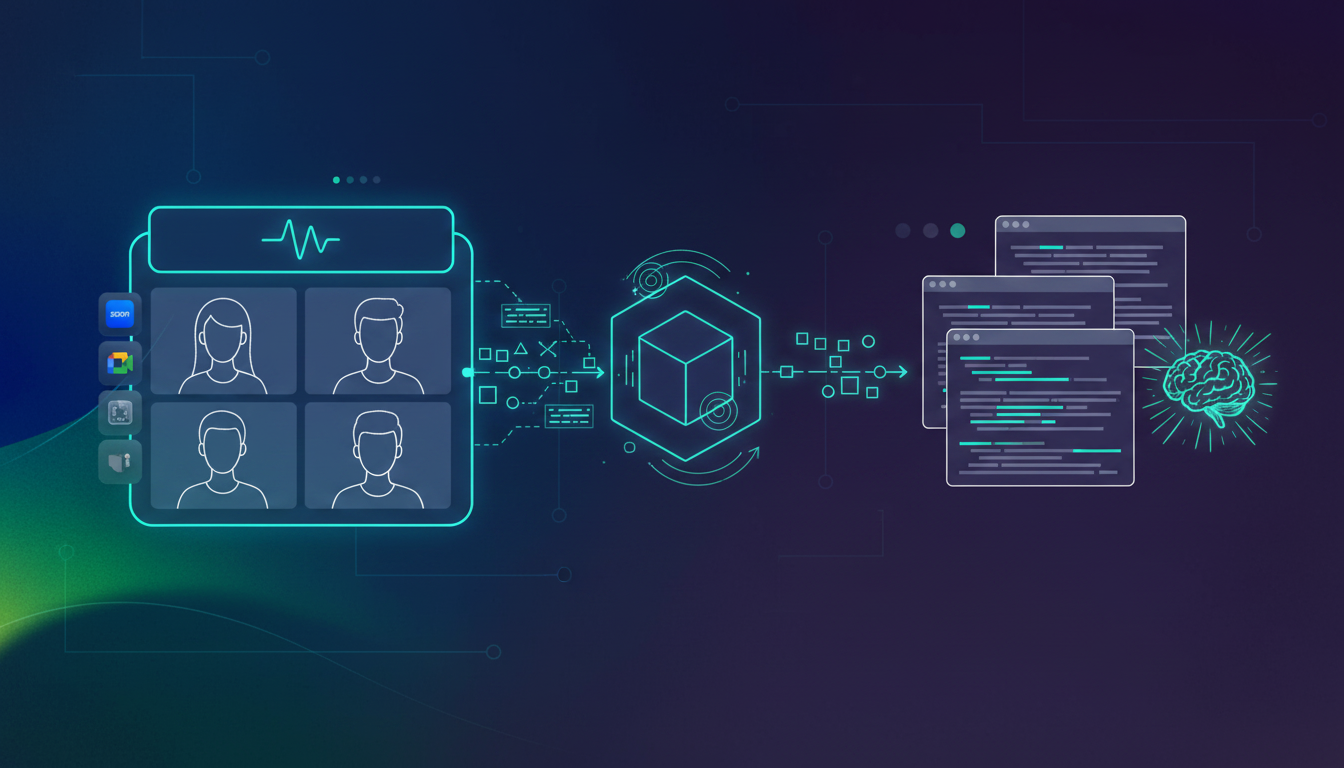
MCP Server Architecture for Meeting Data
The Model Context Protocol is an open standard that lets developers build secure, two-way connections between data sources and AI-powered tools. Claude Code connects via MCP, with MCP servers granting access to tools, databases, and APIs. Spinach’s MCP server implementation gives Claude Code searchable access to your organization’s full meeting corpus, no manual exports or copy-paste required.
Org-Wide Capture vs. Point Integration
Most recording tools work meeting-by-meeting. Spinach captures at the organizational level, meaning Claude Code gets consistent, structured data across every team and project with Google Meet and other platforms.
Governance and Security When Sharing Zoom Data with Claude Code
Routing Zoom transcripts into Claude Code means technical discussions, customer details, and proprietary architecture decisions flow through an AI system. That requires proper controls. Enterprise-grade systems use isolation, encryption, and controls, with organizations retaining full ownership over their data and how it’s governed.
Preventing Shadow AI in Development Teams
Shadow AI is expanding rapidly, with a 2024 survey finding 55% of employees using AI tools their organization never approved. Centralized governance keeps developers from routing sensitive transcripts through ungoverned channels.
Governance Control | Implementation | Benefit |
|---|---|---|
Access Policies | Meeting-level permissions tied to org directory | Only authorized developers access sensitive transcripts |
Zero Data Retention | Contractual agreements with AI providers | Meeting content never used for model training |
Audit Logs | Immutable records of transcript access | Full compliance trail for security reviews |
Regional Deployment | Data residency controls | Meets sovereignty requirements for compliance-driven industries |
Meeting data supports regional storage requirements including Europe, North America, and Asia Pacific, giving compliance-driven organizations full sovereignty control.
Which Teams Benefit Most from Claude Code Having Zoom Context
Different engineering functions extract distinct value when Claude Code can reference Zoom transcripts alongside code context.
Engineering Teams
Development teams use Claude Code with Zoom context to implement features that match specifications from refinement sessions, resolve bugs by referencing error discussion transcripts, and give new engineers searchable access to historical architecture discussions.
Product Teams
Product managers draft technical specs from discovery calls, validate that implementations align with planning requirements, and generate API documentation from stakeholder discussions. With transcript access, AI project managers can automate status updates and track deliverables across recorded planning sessions.
DevOps and Infrastructure Engineering
Teams cut incident investigation time by 80%. With Zoom transcripts from incident response calls, infrastructure engineers can automate post-mortem documentation and implement fixes tied directly to root causes discussed during war rooms.
Technical Leadership
Engineering leaders use Claude Code with full meeting corpus access to identify recurring technical debt themes across retrospectives, surface cross-team dependencies from standup transcripts, and generate executive summaries from architecture review recordings that sync with project management tools.
What to Look for in a Zoom Transcript Layer for Claude Code Integrations
Not every transcript tool is built for Claude Code integration. A few criteria separate viable infrastructure from tools that will hit a wall in production.
Transcript Quality and Speaker Attribution
Speaker diarization is required since transcripts must identify who said what. Without speaker labels, AI cannot assign ownership reliably. Claude Code needs to know a senior engineer flagged a security concern, with the authority and context that matters.
Integration Architecture and Openness
Look for MCP support, REST APIs, webhooks, and native connectors to tools like Spinach AI integrates with Slack, Jira, Linear, and Confluence. A closed system limits what Claude Code can actually access. The Model Context Protocol provides a standardized way to connect LLMs with needed context, making it a key signal of integration readiness.
Centralized vs. Siloed Data Architecture
Evaluation Criterion | Centralized Layer | Point Tool |
|---|---|---|
Cross-team visibility | Full org access with permissions | Limited to single team or function |
Integration flexibility | MCP, API, webhooks, native connectors | Typically closed or limited export |
Governance controls | Org-wide policies and audit | User-level or none |
Context scope | Query across all meetings | Single meeting or project scope |
Point solutions cap what Claude Code can reason across. Centralized architecture is the difference between a coding agent with partial memory and one with full organizational context across Notion and other knowledge bases.
Yes. Spinach’s MCP server gives Claude Code direct access to your Zoom transcripts through the Model Context Protocol, with no custom development required. The connection works out-of-the-box, giving your coding agent searchable access to your organization’s full meeting corpus.
Connect Spinach’s MCP server to Claude Code through the Model Context Protocol integration. Spinach automatically captures your Zoom meetings, structures transcripts with speaker attribution, then exposes that content through MCP so Claude Code can query and reference meeting context while coding.
Centralized layers give Claude Code access to query across all meetings with org-wide policies and governance, while point tools limit the agent to single meetings or projects with no cross-team visibility. A centralized architecture turns Claude Code into an agent with full organizational memory instead of partial context.
Meeting transcripts contain technical decisions and proprietary information that require proper controls. Choose a system with meeting-level access policies, zero data retention with AI providers, audit logs, and regional deployment options to keep sensitive conversations governed and compliant.
Manual exports create a disconnected workflow where Claude Code can’t query across meetings or access updated context automatically. Spinach’s MCP server gives Claude Code live, searchable access to your entire meeting history, so the agent always works with current information and can surface decisions made weeks or months ago.
Claude Code respects meeting-level permissions tied to your organization’s directory. You can only query transcripts from meetings you attended or have explicit access to through admin-granted permissions. Access policies prevent unauthorized developers from surfacing sensitive conversations outside their scope.
Connect Spinach’s MCP server to Claude Code through the Model Context Protocol. This gives your coding agent instant, searchable access to your entire meeting history with zero manual setup or custom development required.
MCP servers provide live, bidirectional access so Claude Code can query meeting data on demand while coding. APIs require you to build custom integration logic and manage data syncing yourself. MCP is the faster, more maintainable path for most teams.
Claude Code queries Spinach’s meeting corpus based on your prompts, code context, and related topics. When you’re fixing a bug, it can surface error discussions from recent standups. When implementing features, it pulls relevant requirements from planning sessions automatically.
Spinach offers single-tenant deployments and regional data residency controls that meet strict sovereignty requirements. Your meeting transcripts can be stored within approved geographic regions and never leave your organization’s infrastructure perimeter.
Yes. Claude Code generates more accurate implementations when it can reference actual stakeholder conversations instead of inferring requirements from code alone. Transcript context reduces misaligned outputs by grounding the agent in real decisions and edge cases discussed in meetings.
Spinach’s access controls let you exclude sensitive meetings from Claude Code’s query scope. You can also configure compliance agents to flag high-risk conversations before they’re indexed, giving your security team review and deletion rights over transcript data.
Use Spinach’s MCP server, APIs, and webhooks to expose meeting data through standardized interfaces. That way your transcript layer works with Claude Code, GitHub Copilot, Cursor, and any future coding agent without rebuilding integrations from scratch.
When your development team builds customer-facing features or fixes reported bugs. Customer call transcripts give Claude Code direct access to user pain points, feature requests, and reproduction steps that would otherwise get lost in translation through product managers or support tickets.
Yes, but transcript quality matters. Claude Code needs speaker-attributed transcripts with topic segmentation to extract actionable requirements. Spinach structures Zoom recordings with speaker labels and agenda markers so Claude Code can parse who decided what and why.
What you should do now
Now that you've read this article, here are some things you should do:
- You should check out our library of meeting agenda templates for every type of meeting.
- You should try Spinach to see how it can help you run a high performing org.
- If you found this article helpful, please share it with others on Linkedin or X (Twitter)

